Analyzing Indian Linguistic Corpora for Financial Literacy Data
Over the past two weeks, I have been conducting quantitative analysis on linguistic datasets of the 22 recognized languages in India. Using AI, I was able to extract the percentage of financial literacy terms present in the corpus. Initially, I was going to start directly comparing these percentages to the financial literacy rates of individuals in those language groups. However, I noticed certain distinct trends related to the scripts, zones, and areas where the languages are primarily used. As a result, I decided to visualize this information to get a better understanding.



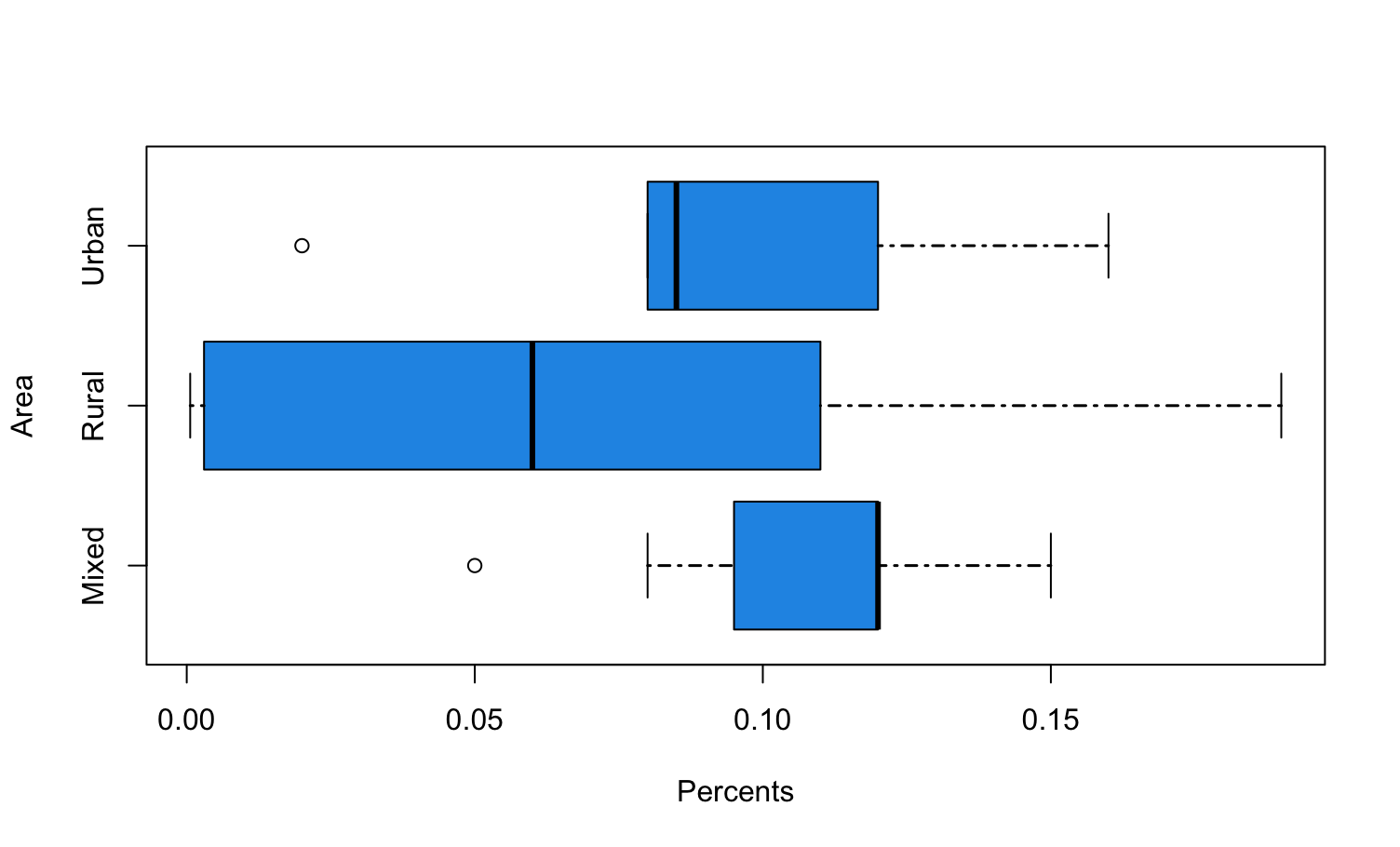
Visualizing the data allowed me to pinpoint variables that would be helpful in exploring once I reach the qualitative aspect of my project.
In the coming weeks, I look forward to producing a linear regression in relation to financial literacy outcomes, learning about the cultural and socioeconomic factors that affect financial literacy understanding, and exploring the implications of this study. Taking into account some of the limitations of my study, such as the accuracy of AI, I believe this methodology will still be able to open doors in computational linguistics research. I am excited to see where my analysis takes me!

Please sign in
If you are a registered user on Laidlaw Scholars Network, please sign in